人声分离技术的重要性
在音频处理和音视频编辑领域,人声分离技术扮演着至关重要的角色。通过快速、精准地分离人声,可以提高音频的清晰度和可听性,使得听众更易于专注于人声内容,从而提升用户体验。
在过去,人声分离通常需要复杂的处理步骤和专业的软件工具,耗时且效果不佳。传统方法往往需要人工干预,无法实现快速高效的人声分离,限制了音频编辑的效率和质量。
快剪辑人声分离技术的优势
快剪辑人声分离技术采用先进的人工智能算法,能够快速准确地识别并分离出音频中的人声部分。这种技术不仅减少了人为干预的需要,提高了处理速度,而且在保留人声清晰度的同时有效减少了背景噪音。
如何实现快速分离人声效果
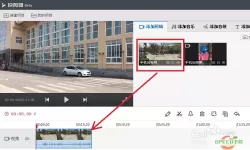
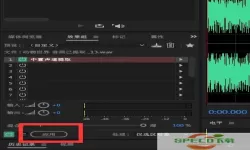
要实现快速分离人声效果,首先需要选择一款优秀的音频处理软件,如Adobe Audition、Audacity等。然后,导入需要处理的音频文件,在软件中选择人声分离功能,并根据需要进行调整参数。最后,点击处理按钮,软件会自动对音频进行分离处理,生成分离后的人声文件。
快剪辑人声分离技术的应用场景
快剪辑人声分离技术广泛应用于音频处理、视频剪辑、语音识别等领域。在视频剪辑中,可以通过分离人声实现对背景音乐和音效的调整;在音频处理中,可以使得录音更加清晰易懂;在语音识别领域,可以提升识别准确度和效率。
结语
快剪辑人声分离技术的出现,极大地提升了音频处理和音视频编辑的效率和质量。通过快速分离人声效果,用户可以更加方便地进行音频处理和编辑,创造出更具有吸引力和专业性的作品,进一步提升用户体验和观众满意度。